Sanctions Explorer: How We Built It
When building the Sanctions Explorer tool, we used public data to make it easier for researchers and policymakers to understand trends behind sanctions. For the OFAC portion of the data pull, we needed to not only capture current sanctions, but we also needed to structure the historical information to display de-listings and other historical changes in the sanctions regime. Parsing OFAC’s Archive of Changes to the SDN List required finesse and flexibility in the design of our parser code, extensive quality controls, and some hand-alterations in cases of ambiguity.

C4ADS’ Data and Technology team was stood up in 2019 to create custom analytical tools and technologies to power C4ADS’ mission to combat organized crime, corruption, and conflict. Our team leverages the power of publicly available information (PAI) and programming to create tools and platforms that power global conflict analysis. From parsing data to machine learning to full-stack development, we cover sophisticated data management and tool creation for C4ADS and everything in between.
For the Sanctions Explorer project, we sought to use public data to make it easier for researchers and policymakers to understand trends behind sanctions. For a more thorough introduction to the motivations behind the Sanctions Explorer project, see our companion blog post.
The Data #
To begin with, we had to get our data from OFAC, the EU, and the UN to display on the website. The UN and the EU structure their data related to currently sanctioned entities, so for those two authorities we are only able to collect data moving forward.
For the OFAC portion, we needed to capture current sanctions, but we also needed to structure the historical information to display de-listings and other historical changes in the sanctions regime. We sourced our raw data from the website of the United States Department of the Treasury and downloaded the Office of Foreign Assets Control’s (OFAC) Archive of Changes to the SDN List in .txt format. The archive includes historical OFAC data from 1994 to the present, though the formatting of the data varies widely across those years.
Between 1994 and 2019, the consistency of formatting in the .txt files improved greatly, which made parsing these documents possible. Below we compare an excerpt from the 1994 Changes to the SDN List to an excerpt from the 2019 Changes to the SDN List.
We see that the 1994 file has formatting that varies significantly – from text clearly meant to be read as a narrative by humans, to text written in a way that could be parsed by machine. For comparison sake, observe the differences between the two excerpts shown below. The first is from the 1994 SDN listing, which mentions more than six different explicit entities with varying information about each entity in the same paragraph. The formatting and style of entries made in the years 1994 and 1995 made it impossible to reliably parse the data from those years, so the data from the years 1994 and 1995 had to be hand-parsed.
The second excerpt from the 2019 SDN list is much more clear. Notice how this excerpt references only one entity between new line characters, maintains consistent organization of each entity’s information throughout each entry, and clearly specifies the date, action, and programs associated with each entry. This systemic style of writing allows us to parse this information out of the text files programmatically.
The Process #
Parsing OFAC’s Archive of Changes to the SDN List required finesse and flexibility in the design of our parser code, extensive quality controls, and some hand-alterations in cases of ambiguity.
Below, we primarily discuss the design of our parser code.
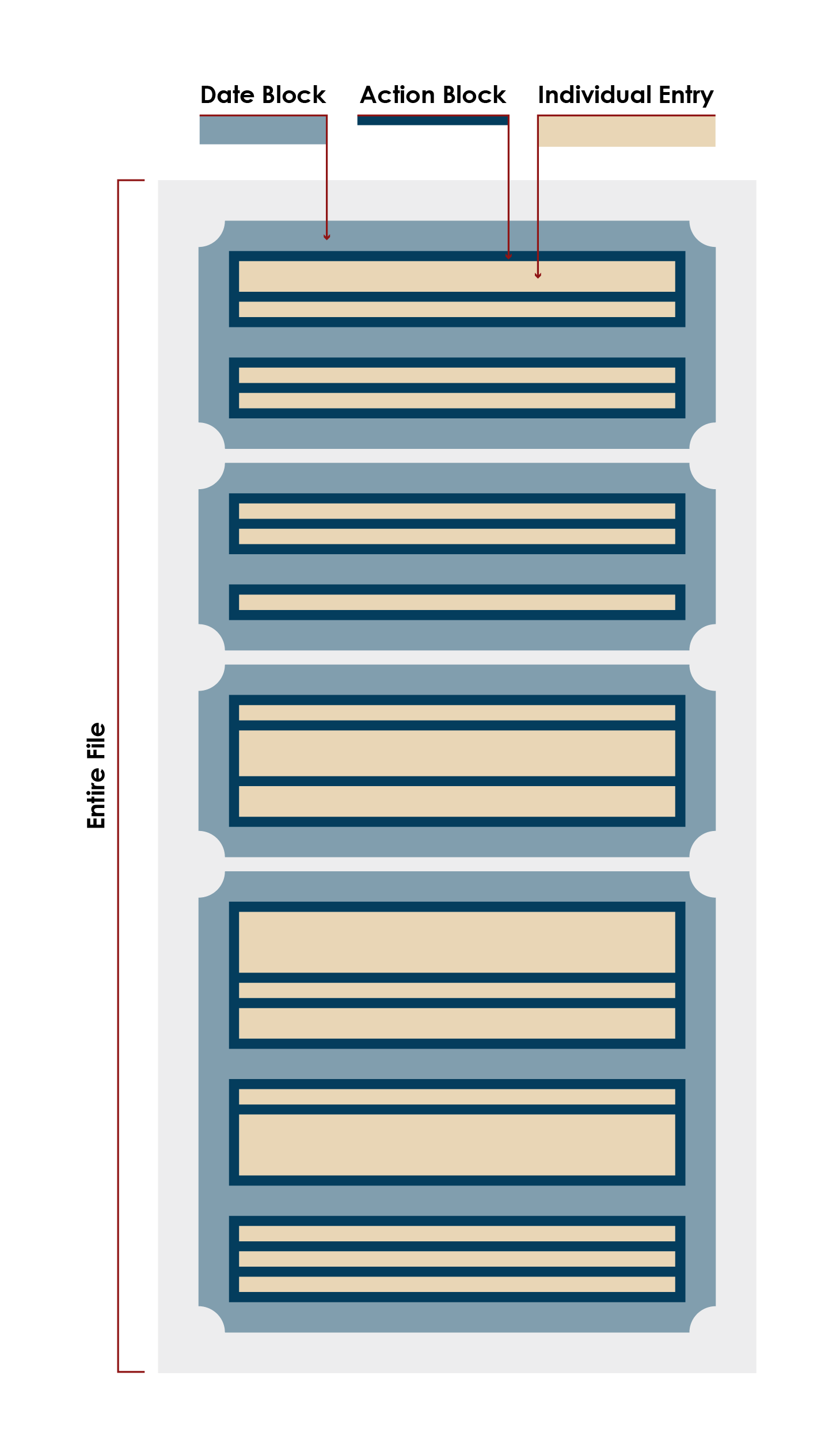
The .txt files are, to more and lesser degrees across the years, organized by date, program, and action, as shown in the graphic to the left.
Each year’s .txt file, represented by the light blue box, contains multiple dates on which entities were either added to, deleted from, or modified in the Changes to SDN List.
Each medium blue block represents a set of entries that were all added to the Changes to SDN List on a specific date.
Each navy blue block represents a set of entries that share that same action and the same previously specified date.
Each tan block represents an individual entry and, therefore, an entry’s addition to, deletion from, or modification in the Changes to SDN List.
For example: Consider that the file lists the changes to the SDN list that occurred in any year; we’ll call this year XX.
Then, the first medium blue block might represent Jan 5, XX, the first navy blue block might represent entities added to the SDN list on Jan 5, XX, and the first tan block might represent the addition of John Smith to the SDN list on Jan 5, XX. In this way we are able to define groupings of data and drill in on this with the code.
It should be noted that programs are also listed as a header, but each entry also lists the programs with which it is associated, so we had no need to divide the entries into subsections based on their programs.
Parsing each individual entry required breaking down each section to smaller and smaller subsections until individual entries were isolated. The following graphic illustrates the process of continual breakdown of the text with a recursion-inspired approach.
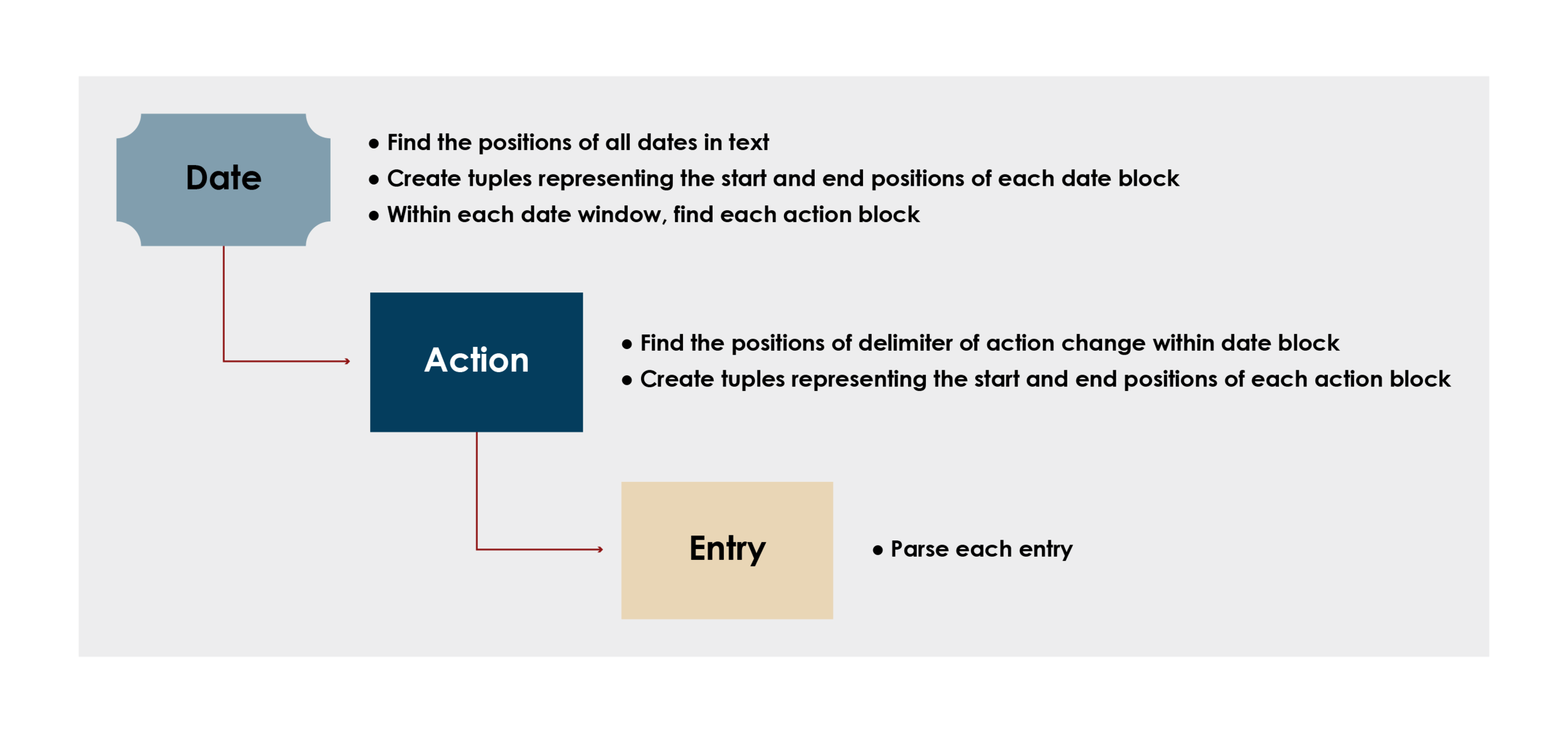
Objects
The parser code was divided into two files: find.py and parse.py. The latter file, parse.py, iterates through the directory of .txt files and creates, for each file, a Parse class object. The Parse class contains the driver code for the parser and helper functions for isolating the individual entries. Additionally, each Parse object maintains the metadata of each entry, such as date, action, and file name.
The find.py file builds off the work of the Parse class object to parse each entry by creating a Find class object. The Find class contains more than 25 helper functions that each search for specific pieces of data that an entry might contain. See example below:
def entity_type(self):
if '(individual)' in self.entry:
return 'individual'
elif '(vessel)' in self.entry:
return 'vessel'
elif '(aircraft)' in self.entry:
return 'aircraft'
else:
return 'entity'
Entry-Level Parsing
The key word in this parse is flexibility. Contending with varying formatting was the overarching challenge, and ultimately could not be conquered completely with the coded parser alone.
Each entry is parsed by a specific combination of functions in the Find class depending on the type of entity in the entry. Each entry contains one entity, which will fall into one of four categories: individual, entity, vessel, or aircraft.
Each type of entry has a number of distinct pieces of information that might be associated with it. For example, an individual might have a nationality, while an aircraft will not. Conversely, an aircraft might have a tail number, while an individual will not. We avoid mis-parsing the data by only looking for what should be associated with a given entity.
The information in each entry is not consistently ordered, so we did a keyword search to populate most fields.
An example of one such function which extracts dates of birth is seen below:
def dob(self):
final = []
pattern1 = r'DOB (.+?);'
dobs = re.findall(pattern1, self.entry, re.DOTALL)
if not dobs:
pattern3 = r'DOB:(.+?);'
pattern2 = 'DOB (.+?)(?<!;)\('
dobs = re.findall(pattern1, self.entry, re.DOTALL) + re.findall(pattern2, self.entry, re.DOTALL) + re.findall(pattern3, self.entry, re.DOTALL)
if not dobs:
return None
for d in dobs:
dob = d
if 'DOB' in d:
dob = re.sub('DOB', '', d)
final.append(dob.strip(string.punctuation).strip())
return final
When looking through the above code, one notices that three regex patterns are used instead of one consolidated pattern. We use one primary pattern (pattern1 = r’DOB (.+?);’) which catches the standard formatting of dates of birth, but we allow for possible anomalies with the second two patterns.
Unfortunately, a few fields (such as the address of an individual or the call sign of a vessel) both have no keyword and are not guaranteed to be in the entry. We used other markers, such as name, which came first in each entry, as flags to capture addresses and call signs. See an example below:
def vessel_type(self, name, flag): #sandwich flag and vessel name
pattern1 = re.compile(r'Vessel Type(.*?);')
matches1 = re.findall(pattern1, self.entry)
matches3 = []
if name and flag:
pattern2 = re.compile(r''.format(name=name, flag=flag[0]))
matches3 = re.findall(pattern2, self.entry)
else:
pattern2 = re.compile(r'^{}\((.*?)\)(.*?);'.format(name))
matches2 = re.findall(pattern2, self.entry)
for match in matches2:
matches3.append(match[2])
matches = matches1 + matches3
if not matches:
return None, None, None, None
numbers = []
dwt = grt = call_sign = None
for match in matches:
number = match
if match == '' or match == ' ':
continue
if '(vessel)' in match:
continue
if 'DWT' in number or 'GRT' in number:
tokens = match.split()
matching = [s for s in tokens if 'DWT' in s]
if matching:
dwt = matching[0].strip()
if dwt == 'DWT':
dwt = ' '
number = number.replace(dwt, ' ')
matching = [s for s in tokens if 'GRT' in s]
if matching:
grt = matching[0]
number = number.replace(grt, '')
if re.search(r'\([A-Z0-9 ]\)', number) is not None:
call_sign = re.search(r'\([A-Z0-9 ]\)', number)
if call_sign:
call_sign = call_sign.group()
number = number.replace(call_sign, '')
if ')' in match:
number = match.split(')')[1]
number = number.strip()
numbers.append(number)
if not numbers:
numbers = None
if dwt == ' ':
dwt = None
return numbers, dwt, grt, call_sign
The Final Product #
Ultimately, we wrote the parsed data out to a master .csv file to use in the backend of the Sanctions Explorer website. The parser code was used to create a master database of historical OFAC sanctions that will be searchable through the platform. Newer data in the website will be derived from the XML file released by OFAC, as that includes data that isn’t included in the text files.